자기 진화형 에이전트와 사람의 역할
- 에이전트의 진화: 메모리에서 스킬로, 그리고 자기 진화로
- 초기 단계: 리플렉션과 메모리
- 운영체제로서의 메모리: MemGPT
- 스킬 추상화와 재사용: Voyager
- 2024~2025년: 메모리와 스킬의 고도화
- 메모리 메커니즘의 정리와 구조화
- 자동 스킬 발견과 오픈월드 스킬
- 스킬 라이브러리와 자기 개선 루프
- Self-Evolving Agents: SkillRL과 SkillOS
- 스킬을 진화시키는 강화학습: SkillRL
- 스킬 큐레이션을 배우는 운영체제: SkillOS
- 에이전트 발전 흐름 요약
- 나의 생각: 기억보다 큐레이션
- 사람에게 남는 자리
- 장기 전망과 서비스화
- 결론
- 참고문헌
자기 진화형 에이전트와 사람의 역할
메모리, 스킬, 큐레이션, 그리고 사람이 남길 자리
최근 몇 년 사이 AI 에이전트 연구는 단순한 모델 호출을 넘어서 경험을 축적하고 재사용하는 시스템을 목표로 빠르게 진화하고 있습니다. 초기에는 실패를 언어로 기록하는 리플렉션(reflection)이 중심이었다면, 이후에는 긴 맥락을 다루기 위한 메모리 계층화, 실행 가능한 스킬 라이브러리, 자동 스킬 발견, 그리고 강화학습으로 스킬을 큐레이션하는 자기 진화형 에이전트로 관심이 이동했습니다.
이 글에서는 Reflexion → MemGPT/Generative Agents → Voyager → 2024~2025년의 메모리·스킬 고도화 → SkillRL/SkillOS로 이어지는 흐름을 정리하고, 이러한 변화 속에서 사람에게 어떤 역할이 남는지 생각해봅니다.
에이전트의 진화: 메모리에서 스킬로, 그리고 자기 진화로
LLM을 이용한 에이전트가 등장한 이후 연구는 크게 다음과 같은 단계를 거치며 발전해 왔습니다. 핵심 흐름은 경험을 남기는 것에서 경험을 구조화하는 것으로, 다시 구조화된 경험을 언제 어떻게 쓸지 학습하는 것으로 이동합니다.
초기 단계: 리플렉션과 메모리
초기 연구들은 에이전트가 실패에서 배우도록 하기 위해 언어적 리플렉션을 도입했습니다. Reflexion은 모델 가중치를 업데이트하지 않고, 작업 수행 결과와 피드백을 언어로 기록해 에피소드 메모리 버퍼에 저장합니다. 다음 시도에서 이 텍스트를 참고하여 더 나은 결정을 내리도록 유도하는 방식입니다. 이러한 접근은 다양한 작업에서 기존 에이전트 대비 성능을 높였지만, 기록이 늘수록 리플렉션의 품질이 일관되지 않고 구조화가 부족하다는 단점이 있었습니다.
비슷한 시기 Generative Agents는 개인의 경험을 자연어 메모리로 저장하고, 관찰·계획·리플렉션을 결합해 그럴듯하고 일관된 행동을 생성하는 구조를 제안했습니다. 이 연구는 메모리가 단순 검색 대상이 아니라 에이전트의 장기적 정체성과 행동 일관성을 만드는 기반이 될 수 있음을 보여주었습니다.
운영체제로서의 메모리: MemGPT
이후 MemGPT는 한정된 컨텍스트 윈도우 문제를 해결하기 위해 **가상 컨텍스트 관리(virtual context management)**라는 개념을 제안했습니다. 기존 LLM은 길이가 긴 문서나 오랜 대화를 한 번에 처리하기 어렵습니다. MemGPT는 전통적인 운영체제의 계층형 메모리 시스템처럼 빠른 메모리와 느린 메모리 간 데이터를 이동시켜, 제한된 컨텍스트 윈도우 안에서도 더 큰 맥락을 사용할 수 있는 것처럼 보이게 합니다.
다만 MemGPT의 메모리 관리는 장기 보상에 의해 학습된 큐레이션 정책이라기보다, 설계된 메모리 계층과 도구 호출 규칙에 의존합니다. 따라서 어떤 경험이 장기적으로 재사용 가치가 있는지 학습하는 문제는 여전히 별도의 과제로 남습니다.
이 아이디어는 상용 개발 에이전트에서 가장 먼저 프로젝트 지침 파일의 형태로 자리 잡았습니다. Claude Code의 CLAUDE.md, OpenAI Codex의 AGENTS.md, Gemini CLI의 GEMINI.md는 이름은 다르지만 모두 비슷한 역할을 합니다. 저장소 구조, 코딩 스타일, 테스트 방법, 금지된 작업, 선호하는 패키지 매니저 같은 반복 지침을 에이전트가 읽을 수 있는 파일로 남기는 것입니다. 이는 완전한 자동 장기기억이라기보다, 사람이 선별한 맥락을 에이전트에게 주입하는 명시적 큐레이션에 가깝습니다. 중요한 점은 세 서비스가 서로 다른 이름을 쓰면서도 거의 같은 인터페이스로 수렴하고 있다는 점입니다. 에이전트에게 “이 프로젝트에서는 이렇게 일한다”는 작업 계약을 제공하는 방식은 이제 개발 에이전트의 사실상 표준 기능이 되고 있습니다.
스킬 추상화와 재사용: Voyager
2023년 발표된 Voyager는 마인크래프트 세계에서 스킬 라이브러리 개념을 선보였습니다. 에이전트가 탐험을 통해 습득한 행동을 실행 가능한 코드 조각으로 저장하고 재사용하는 방식입니다. Voyager는 자동 커리큘럼, 실행 오류에 기반한 반복 프롬프트, 자기 검증을 통해 점차 복잡한 행동을 습득했습니다.
중요한 점은 Voyager가 경험을 단순 텍스트가 아니라 프로그램 단위의 스킬로 저장했다는 점입니다. 이러한 스킬은 긴 시간에 걸친 행동을 담아내고, 해석 가능하며, 조합해서 쓸 수 있습니다. 특히 동일한 마인크래프트 환경 안에서 새로운 목표나 상황에 재사용될 수 있음을 보여주었습니다. 이는 단순히 “무엇을 기억할 것인가”를 넘어 “경험을 어떤 실행 가능한 단위로 추상화할 것인가”라는 질문을 열었습니다.
그러나 스킬이 많아지면 어떤 스킬을 쓸 것인지, 어떤 스킬이 쓸모없는지를 판단하는 문제가 새롭게 등장합니다. Voyager 이후의 연구들은 스킬을 단순 저장하는 것을 넘어, 스킬을 발견하고 선별하며 진화시키는 방법을 모색하기 시작했습니다.
현실의 개발 도구에서도 같은 변화가 나타납니다. Claude Code의 Skills, Hermes의 Skills System, Pi의 Skills, 그리고 Agent Skills 표준은 모두 경험을 단순한 프롬프트가 아니라 SKILL.md, 참고 문서, 스크립트, 템플릿, 에셋을 포함한 절차 지식 패키지로 다루려 합니다. 반복해서 붙여 넣던 체크리스트나 긴 작업 절차를 항상 컨텍스트에 넣는 대신, 필요할 때만 로드되는 스킬로 분리하는 것입니다. 이 점에서 Voyager의 코드 스킬 라이브러리는 마인크래프트라는 연구 환경을 넘어, 실제 개발 에이전트의 스킬 시스템으로 이어지는 개념적 원형처럼 보입니다.
2024~2025년: 메모리와 스킬의 고도화
2024~2025년 연구 흐름은 2023년의 “메모리와 스킬 라이브러리” 아이디어를 더 현실적인 방향으로 확장했습니다. 이 시기의 핵심은 세 가지입니다. 첫째, 메모리를 더 체계적으로 조직하려는 시도입니다. 둘째, 스킬을 사람이 직접 정의하지 않고 자동으로 발견하려는 시도입니다. 셋째, 스킬 라이브러리를 자기 개선 루프와 결합하려는 시도입니다.
메모리 메커니즘의 정리와 구조화
2024년에는 LLM 기반 에이전트의 메모리 메커니즘을 체계적으로 정리하려는 흐름이 등장했습니다. A Survey on the Memory Mechanism of Large Language Model based Agents는 에이전트가 장기적이고 복잡한 환경 상호작용을 수행하기 위해 메모리가 왜 필요한지, 기존 연구들이 어떤 방식으로 기억을 저장·검색·관리하는지 정리했습니다. 이는 메모리가 개별 연구의 부속 기능이 아니라, 자기 진화형 에이전트의 핵심 구성 요소로 다뤄지기 시작했음을 보여줍니다.
2025년의 A-MEM은 여기서 한 걸음 더 나아가, 에이전트 메모리를 동적으로 조직하는 agentic memory를 제안했습니다. A-MEM은 제텔카스텐(Zettelkasten) 방식에서 영감을 받아 새로운 기억을 추가할 때 문맥 설명, 키워드, 태그 등을 포함한 구조화된 노트를 만들고, 기존 기억과의 연결을 동적으로 형성합니다. 기억을 단순히 벡터 데이터베이스에 넣고 검색하는 수준을 넘어, 기억 사이의 관계를 조직하는 방향으로 이동한 것입니다.
비슷하게 MemInsight는 장기 메모리의 크기가 커질수록 의미 구조화와 검색 품질이 중요해진다는 문제를 다뤘습니다. 이 연구는 과거 상호작용을 자율적으로 보강해 의미 표현과 검색을 개선하는 접근을 제안했고, 추천·질의응답·이벤트 요약 같은 과제에서 메모리 증강이 성능을 높일 수 있음을 보였습니다.
Hermes의 Persistent Memory는 이런 문제의 실용적 구현에 가깝습니다. Hermes는 모든 대화 기록을 무한히 컨텍스트에 넣지 않고, MEMORY.md와 USER.md에 꼭 필요한 환경 사실, 프로젝트 관례, 사용자 선호만 작고 선별된 메모리로 유지합니다. 반면 특정 과거 대화를 찾아야 할 때는 세션 검색을 사용합니다. 즉 “항상 필요한 기억”과 “필요할 때 검색할 기록”을 분리합니다. 이는 메모리 과잉 문제에 대한 제품 수준의 큐레이션 전략입니다.
자동 스킬 발견과 오픈월드 스킬
스킬 쪽에서도 2024년부터 중요한 변화가 나타났습니다. Agentic Skill Discovery는 로봇 제어 맥락에서 LLM이 장면 정보를 바탕으로 과제를 제안하고, 그 과제를 통해 새로운 기초 스킬을 발견하는 프레임워크를 제안했습니다. 기존 방식은 사람이 복잡한 작업을 원자적 행동으로 나누거나, 가능한 조합을 무작정 탐색하는 경우가 많았습니다. 그러나 이런 방식은 초기 스킬 라이브러리에 없는 능력을 발견하기 어렵습니다. Agentic Skill Discovery는 LLM을 사용해 의미 있는 과제 제안과 스킬 발견을 연결했다는 점에서 중요합니다.
마인크래프트 계열에서는 Odyssey가 Voyager 이후의 한계를 넓혔습니다. Voyager가 자동 커리큘럼으로 마인크래프트의 행동 폭을 넓히긴 했지만 오픈월드 활동 전반을 포괄하는 라이브러리까지는 가지 못했다면, Odyssey는 40개의 primitive skill과 183개의 compositional skill로 이루어진 오픈월드 스킬 라이브러리를 제안했습니다. 이는 스킬 라이브러리가 단순히 특정 목표를 달성하기 위한 도구 모음이 아니라, 더 넓은 환경 탐색을 가능하게 하는 행동 자산으로 확장될 수 있음을 보여줍니다.
2025년의 Automated Skill Discovery for Language Agents through Exploration and Iterative Feedback은 스킬 획득을 위한 학습 데이터 생성 문제를 직접 다룹니다. 사람이 trajectory(작업 수행 궤적)를 수집하면 비용이 크고, LLM이 직접 학습 과제를 제안하면 실제로 가능한지 모르거나 이미 쉬운 과제만 생성할 수 있습니다. 이 연구는 EXIF라는 프레임워크를 통해 탐험 에이전트가 먼저 환경을 탐색하고, 그 결과를 바탕으로 목표 에이전트가 배워야 할 행동을 구성하는 방식을 제안했습니다.
제품 생태계에서는 자동 스킬 발견이 아직 완전히 학습된 형태로 구현되었다기보다, 사람이 만든 스킬과 확장을 공유하는 방식으로 먼저 나타나고 있습니다. Gemini CLI Extensions는 프롬프트, MCP 서버, 커스텀 명령어를 하나의 확장 패키지로 묶고, pi.dev Packages는 스킬·확장·프롬프트 템플릿을 설치 가능한 패키지처럼 배포합니다. pi-subagents, pi-mcp-adapter, context-mode 같은 패키지는 에이전트의 능력이 개별 설정 파일을 넘어 공유 가능한 모듈로 유통되고 있음을 보여줍니다.
다만 “사람이 큐레이션한다”는 것이 늘 손으로 직접 만든다는 뜻은 아닙니다. 제품에는 아직 안 들어왔어도 사용자 커뮤니티에서는 이미 단순한 형태의 자동 학습 흐름이 자리 잡고 있습니다. Claude Code의 Stop 훅으로 세션 종료 시 transcript에서 반복 실수·규칙·노하우를 자동 추출해 큐에 적재하고, 다음 세션에서 사용자가 검토해 메모리·CLAUDE.md·hook으로 승격하는 패턴이 대표적입니다. claude-reflect-system, self-learning-claude, everything-claude-code의 continuous-learning skill, oh-my-opencode의 /skillify, 그리고 내가 쓰는 /learning-review 같은 워크플로가 모두 이 흐름에 속합니다. 이는 EXIF의 “탐험 → 학습 과제 구성”이나 SkillOS의 “Curator가 SkillRepo를 업데이트”의 사람-루프 버전에 가깝습니다. 발견과 승격을 모두 자동화한 단계는 아니지만, 적어도 “어떤 경험을 스킬 후보로 끌어올릴지”는 이미 자동화되고 있습니다.
또 하나의 흐름은 에이전트 종속(lock-in)을 피하려는 노력입니다. 스킬 패키지와 MCP가 단순한 재사용 단위를 넘어 에이전트에 무관한 능력 형식을 지향한다는 점에서 그렇습니다. pi.dev Packages가 Claude·Codex·OpenCode·Gemini 어디서나 같은 패키지를 설치할 수 있게 한다면, Microsoft의 APM(Agent Package Manager)은 한 걸음 더 나아가 apm.yml 한 장에 선언한 의존성을 여러 코딩 에이전트에서 동일하게 풀어 씁니다. apm.lock.yaml로 commit SHA까지 버전을 고정해 npm·pip 수준의 재현성을 제공합니다. 학술 연구가 “스킬 라이브러리를 한 에이전트 안에서 어떻게 진화시킬까”를 묻는다면, 현재 생태계는 그 위에 “스킬을 어느 에이전트에서도 쓸 수 있게 어떻게 표준화할까”라는 질문을 덧대고 있는 셈입니다.
연구가 “스킬을 어떻게 자동으로 발견할 것인가”를 묻는다면, 현재 제품과 커뮤니티는 그보다 한 단계 아래에서 “사람이 발견한 경험을 재사용 가능하게 포장하고, 에이전트에 종속되지 않게 배포하며, 추출 단계의 일부를 자동화하는” 문제를 먼저 풀고 있습니다.
스킬 라이브러리와 자기 개선 루프
2025년 말의 Reinforcement Learning for Self-Improving Agent with Skill Library는 스킬 라이브러리를 자기 개선 루프와 직접 결합하려는 흐름을 보여줍니다. 이 연구는 Skill Augmented GRPO for self-Evolution, 즉 SAGE라는 프레임워크를 제안합니다. 에이전트가 유사한 작업 체인을 순차적으로 수행하면서 이전 작업에서 생성된 스킬을 축적하고, 이후 작업에서 이를 활용하도록 강화학습을 적용합니다.
이 흐름은 2026년의 SkillRL과 SkillOS로 이어지는 디딤돌입니다. 2024~2025년 연구가 “메모리와 스킬을 어떻게 더 잘 만들 것인가”에 집중했다면, 2026년 연구는 “만들어진 스킬을 어떻게 장기 보상 관점에서 큐레이션하고 진화시킬 것인가”로 초점을 이동시킵니다.
이 지점에서 개발자들의 실천도 중요해집니다. 실제 현장에서는 반복되는 PR 리뷰 코멘트, 릴리스 절차, 성능 회귀 분석, 장애 대응, 문서 작성 방식이 CLAUDE.md, AGENTS.md, GEMINI.md 같은 지침 파일이나 SKILL.md 기반 스킬 저장소로 승격됩니다. 예전에는 숙련자의 노하우가 README, 위키, 개인 dotfiles에 흩어져 있었다면, 이제는 에이전트가 직접 읽고 실행할 수 있는 작업 자산으로 바뀌고 있습니다.
Self-Evolving Agents: SkillRL과 SkillOS
스킬을 진화시키는 강화학습: SkillRL
2026년 초에 발표된 SkillRL은 LLM 에이전트가 과거의 경험을 토대로 고수준 행동 패턴을 자동으로 추출하고, 이를 계층적 스킬 라이브러리인 SkillBank에 저장한 뒤 강화학습 과정에서 스킬과 정책을 함께 진화시키는 프레임워크입니다.
SkillRL은 노이즈가 많은 원시 trajectory를 그대로 저장하는 기존 방법이 일반화에 방해가 된다는 문제를 지적합니다. 그래서 경험 기반 증류(distillation)를 통해 재사용 가능한 스킬을 발견하고, 스킬 라이브러리와 정책이 서로 영향을 주며 재귀적으로 진화하는 메커니즘을 도입합니다. 핵심은 경험을 단순 기록이 아니라 정책 개선에 기여하는 추상화된 행동 자산으로 바꾸는 데 있습니다.
스킬 큐레이션을 배우는 운영체제: SkillOS
가장 최근 연구인 SkillOS는 “어떤 스킬을 언제 꺼내 써야 하는가”를 해결하기 위해 스킬 큐레이터를 강화학습으로 학습시킵니다. 논문은 에이전트를 **Executor(실행자)**와 **Skill Curator(큐레이터)**로 분리합니다. Executor는 동결된 LLM으로 구체적인 작업을 수행하며, Curator는 경험을 분석해 외부 스킬 저장소인 SkillRepo를 업데이트하고 작업에 맞는 스킬을 선택합니다.
SkillOS의 중요한 포인트는 단순히 메모리를 저장하는 것이 아니라 메모리와 스킬 관리 자체를 학습 대상으로 삼았다는 점입니다. 연구팀은 스킬 관련성에 기반해 작업 스트림을 그룹화하고, 초기 trajectory는 SkillRepo를 업데이트하며, 나중의 관련 작업이 이 업데이트의 효과를 평가하도록 설계했습니다. 그 결과 SkillOS는 메모리 없는 에이전트와 기존 메모리 기반 에이전트보다 효과와 효율 면에서 모두 우수한 성능을 보였고, 큐레이터가 다양한 기반 모델과 작업 영역에도 일반화될 수 있음을 보였습니다.
즉 SkillOS는 “스킬을 저장한다”에서 한 걸음 더 나아가, “스킬 저장소를 어떻게 운영할지 학습한다”는 관점을 제시합니다. 에이전트가 장기적으로 진화하려면 기억과 스킬을 무한히 쌓는 것이 아니라, 무엇을 승격하고 무엇을 버릴지 결정하는 큐레이션 능력이 필요하다는 의미입니다.
다만 현재 상용 서비스는 아직 SkillOS처럼 완전한 자동 큐레이터를 학습하는 단계까지 가지는 않았습니다. 대신 더 현실적인 중간 단계에 있습니다. 사람과 에이전트가 함께 기억을 선별하고, 반복 업무를 스킬로 만들고, 그 스킬을 팀과 생태계에 공유합니다. Claude Skills, Gemini Extensions, Hermes Skills, pi.dev Packages, Agent Skills 표준은 모두 이 반자동 큐레이션 루프의 사례입니다. 연구가 향하는 곳이 자동화된 스킬 큐레이터라면, 현재 제품들이 제공하는 것은 사람이 큐레이션한 경험을 에이전트가 재사용하는 기반 인프라에 가깝습니다.
에이전트 발전 흐름 요약
아래 타임라인은 리플렉션 기반 에이전트부터 스킬 큐레이션까지의 주요 단계를 요약합니다.
- Reflexion (2023) – 실패를 언어로 기록하고 재사용하여 다음 시도에 반영.
- Generative Agents (2023) – 경험을 자연어 메모리로 저장하고, 리플렉션과 계획을 통해 일관된 행동 생성.
- MemGPT (2023) – 계층형 메모리 관리로 긴 컨텍스트를 처리하며 운영체제와 유사한 구조 제공.
- Voyager (2023) – 마인크래프트 환경에서 실행 가능한 코드 스킬 라이브러리를 구축.
- Memory Mechanism Survey (2024) – LLM 에이전트 메모리 연구를 체계화하고 메모리를 자기 진화의 핵심 요소로 정리.
- Agentic Skill Discovery (2024) – LLM이 의미 있는 과제를 제안하고 이를 통해 새로운 기초 스킬을 발견.
- Odyssey (2024~2025) – 마인크래프트 오픈월드 탐색을 위해 primitive skill과 compositional skill을 결합한 스킬 라이브러리 제안.
- A-MEM / MemInsight (2025) – 장기 메모리를 동적으로 조직하고 의미 구조화와 검색 품질을 개선.
- Automated Skill Discovery / EXIF (2025) – 탐험과 반복 피드백을 통해 언어 에이전트의 스킬 발견 과정을 자동화.
- SAGE (2025) – 스킬 라이브러리를 강화학습 기반 자기 개선 루프와 결합.
- SkillRL (2026) – 경험 기반 distillation과 재귀적 스킬 진화를 통해 스킬 라이브러리와 정책을 함께 최적화.
- SkillOS (2026) – 강화학습으로 스킬 큐레이션 정책을 학습하여 메모리와 스킬 사용을 관리.
나의 생각: 기억보다 큐레이션
이 흐름을 압축하면 병목은 기억의 부재에서 기억의 과잉으로 이동합니다. 초기 에이전트에게는 과거를 남기는 능력이 중요했지만, 경험이 충분히 쌓인 뒤에는 무엇을 버리고, 무엇을 일반화하고, 무엇을 스킬로 승격할지가 더 중요해집니다. 따라서 자기 진화형 에이전트의 핵심은 단순한 장기기억이 아니라, 경험을 구조화하고 검증 가능한 행동 자산으로 바꾸는 큐레이션 능력에 있습니다.
여러 연구를 종합하면 지금의 주요 과제는 단순히 많은 메모리를 저장하는 것이 아니라 어떤 경험과 스킬이 의미 있고 언제 재사용해야 하는지를 판단하는 능력을 기르는 데 있습니다. 스킬을 선별하지 않으면 컨텍스트 폭발이 발생하고 노이즈가 늘어나 성능이 오히려 떨어질 수 있습니다. SkillOS가 큐레이션 능력 자체를 강화학습으로 학습시킨 이유가 여기에 있습니다.
그러나 큐레이터를 학습 대상으로 삼는 순간 새로운 위험이 따라옵니다. 잘못 증류된 스킬이 큐레이터의 보상 신호로 거꾸로 흘러 들어가, 오류가 강화되는 폐쇄 루프가 만들어질 수 있습니다. 모델이 잘못된 결론을 한 번 내리는 것과, 그 결론이 스킬로 승격된 뒤 큐레이터가 다시 그 스킬을 우선 호출하도록 학습되는 것은 위험의 차원이 다릅니다. 노이즈가 많은 trajectory가 그대로 정책에 반영되는 문제(SkillRL이 지적한 그 문제)를, 이번에는 큐레이터 학습 단계에서 다시 마주하는 셈입니다.
따라서 스킬 생태계에는 단순한 버전 관리뿐 아니라 테스트·리뷰·모니터링·롤백 같은 소프트웨어 공학의 통제 장치가 필요해집니다. 그리고 그 통제 장치를 누가 설정하고 누가 책임지는지 — 즉 자동화의 바깥에서 자동화를 평가하는 자리 — 가 자연스럽게 다음 질문이 됩니다.
사람에게 남는 자리
여기서 솔직해질 필요가 있습니다. “이해와 판단은 사람의 몫”이라는 익숙한 결론은 본문이 정리한 연구 흐름과 그대로 맞지 않습니다. SkillOS가 보여주듯, 어떤 스킬을 언제 꺼낼지의 큐레이션도 결국 학습 대상이 됩니다. 이해도 판단도 형태에 따라서는 자동화될 수 있고, 그렇게 가져갈 수 있는 부분은 분명히 가져갑니다.
그래도 사람의 자리가 모두 사라지는 것은 아닙니다. 적어도 지금은, 무엇을 좋은 결과로 볼 것인지를 정의하고 그 결과의 책임을 지는 자리에 사람이 있습니다. 이는 능력의 분할(이해는 사람, 실행은 AI)이라기보다 위치의 분할에 가깝습니다. 자동화의 안에서가 아니라, 자동화의 바깥에서 자동화를 평가하는 자리입니다.
이 자리에서 사람에게 남는 일은 크게 네 가지입니다.
- 가치 기준 정의: 자동화가 향해야 할 좋은 결과가 무엇인지 결정합니다.
- 맥락과 설명 가능성: 생성된 스킬과 워크플로가 조직의 규칙·문맥에 부합하는지 점검하고 문서화합니다.
- 결과 평가와 책임: 에이전트가 제안한 행동을 받아들일지 결정하고, 그 결정의 책임을 집니다.
- 거버넌스: 스킬 생태계의 품질과 안전성을 관리하고, 자기 개선 루프가 오류를 강화하지 않도록 통제합니다.
이 영역들은 자동화하기 어렵다기보다, 자동화 자체를 평가하기 위해 자동화 바깥에 있어야 하는 영역입니다. 에이전트가 스스로 코드를 작성하고 워크플로를 진화시켜도, 그 설계를 이해하지 못하면 장애 대응과 유지보수가 불가능해집니다. 이해를 외주화하는 순간, 판단할 자격도 함께 떠납니다. 그래서 사람은 에이전트의 설계자이자 감시자로서 계속 학습해야 합니다.
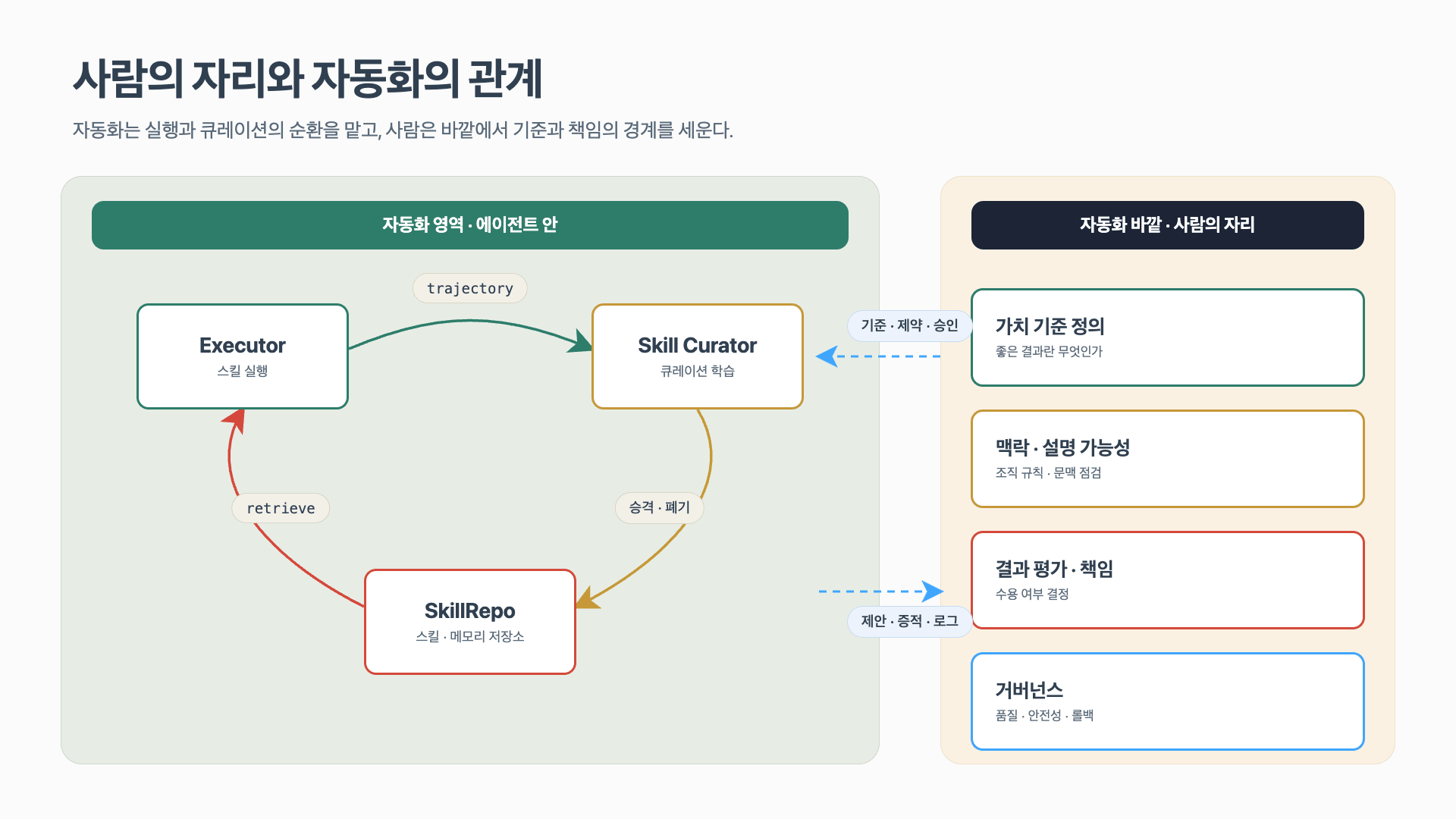 사람의 역할은 자동화 안에서 모든 판단을 대신하는 것이 아니라, 자동화 바깥에서 기준과 책임의 경계를 세우는 것입니다.
사람의 역할은 자동화 안에서 모든 판단을 대신하는 것이 아니라, 자동화 바깥에서 기준과 책임의 경계를 세우는 것입니다.
장기 전망과 서비스화
이 흐름이 계속된다면 개발 에이전트 플랫폼은 단순한 코드 생성 도구가 아니라, 조직의 경험을 저장하고 실행하는 스킬 인프라에 가까워질 것입니다. 이미 프로젝트 메모리, 규칙 파일, 작업 이력, 스킬 패키지, 확장 기능은 제품 기능으로 흡수되고 있습니다. 장기적으로는 Claude, Codex, Gemini, Hermes, pi.dev 같은 도구들이 경험 축적과 스킬 큐레이션 기능을 더 강하게 패키지화할 가능성이 높습니다.
그러나 서비스화가 진행된다고 해서 개인이나 조직의 탐구가 불필요해지는 것은 아닙니다. 더 정확히 말하면, 지금 들이는 시간이 끝까지 자산으로 남을지는 단언할 수 없습니다. 미래 플랫폼이 워크플로 설계와 평가까지 가져가는 방향으로 간다면, 지금의 노력은 박물관 지식에 가까워질지도 모릅니다.
그래도 지금 직접 부딪혀보지 않으면, 나중에 플랫폼이 옳은 방향으로 가고 있는지 평가할 기준 자체가 본인 안에 형성되지 않습니다. 추상화의 안목과 평가의 직관은 부딪혀본 횟수에 비례합니다. 자동화의 수용자로 남을 것인가, 심사자로 남을 것인가의 차이는 거기서 갈립니다. 플랫폼은 스킬을 저장하고 실행하는 틀을 제공할 수 있지만, 어떤 경험을 조직의 자산으로 만들지는 여전히 사람이 결정해야 합니다.
서비스화가 진행되더라도 다음 문제는 계속 남습니다.
- 스킬 아키텍처 설계, 의존성 관리, 거버넌스 등 높은 수준의 설계 문제.
- 조직별 문화와 규칙을 어떻게 스킬로 추상화할지 결정하는 문제.
- 책임과 검증 체계를 수립하는 문제.
따라서 향후의 경쟁력은 더 큰 모델을 갖추는 것보다 누가 더 잘 경험을 축적하고 스킬로 승격하며, 이를 이해 가능한 형태로 유지하는가에 달릴 것입니다. 우리는 이제 프롬프트 엔지니어링의 시대를 지나, 경험과 스킬을 1급 자산으로 다루는 — 잠정적으로 부르자면 Experience Engineering — 시대에 진입하고 있습니다 (UX/CX 분야의 같은 이름과는 다른 의미로 사용합니다).
결론
리플렉션과 메모리에서 시작된 LLM 에이전트 연구는 스킬 추상화와 자동 스킬 발견을 거쳐, 스킬 큐레이션 자체를 학습하는 자기 진화형 운영체제로 향하고 있습니다. 이 여정에서 중요한 것은 기억 자체가 아니라 기억을 선별하고 진화시키는 능력이며, 그 능력 또한 점차 학습 대상이 되어 갑니다.
이해와 판단이 영원히 사람의 몫이라고 단언할 수는 없습니다. 다만 적어도 지금은, 무엇을 좋은 결과로 볼 것인지를 정의하고 그 결과의 책임을 지는 자리에 사람이 있습니다. 이는 능력의 분할이 아니라 위치의 분할입니다. 개발자가 취할 견지는 그 자리를 회피하지 않는 것, 그리고 자동화된 시스템을 계속 이해하려 노력하는 것입니다. 이해를 외주화하는 순간, 판단할 자격도 함께 떠납니다.
참고문헌
- Noah Shinn et al., “Reflexion: Language Agents with Verbal Reinforcement Learning”, arXiv:2303.11366. https://arxiv.org/abs/2303.11366
- Joon Sung Park et al., “Generative Agents: Interactive Simulacra of Human Behavior”, arXiv:2304.03442. https://arxiv.org/abs/2304.03442
- Charles Packer et al., “MemGPT: Towards LLMs as Operating Systems”, arXiv:2310.08560. https://arxiv.org/abs/2310.08560
- Guanzhi Wang et al., “Voyager: An Open-Ended Embodied Agent with Large Language Models”, arXiv:2305.16291. https://arxiv.org/abs/2305.16291
- Zeyu Zhang et al., “A Survey on the Memory Mechanism of Large Language Model based Agents”, arXiv:2404.13501. https://arxiv.org/abs/2404.13501
- Xufeng Zhao, Cornelius Weber, Stefan Wermter, “Agentic Skill Discovery”, arXiv:2405.15019. https://arxiv.org/abs/2405.15019
- Shunyu Liu et al., “Odyssey: Empowering Minecraft Agents with Open-World Skills”, arXiv:2407.15325. https://arxiv.org/abs/2407.15325
- Wujiang Xu et al., “A-MEM: Agentic Memory for LLM Agents”, arXiv:2502.12110. https://arxiv.org/abs/2502.12110
- Rana Salama et al., “MemInsight: Autonomous Memory Augmentation for LLM Agents”, arXiv:2503.21760. https://arxiv.org/abs/2503.21760
- Yongjin Yang et al., “Automated Skill Discovery for Language Agents through Exploration and Iterative Feedback”, arXiv:2506.04287. https://arxiv.org/abs/2506.04287
- Jiongxiao Wang et al., “Reinforcement Learning for Self-Improving Agent with Skill Library”, arXiv:2512.17102. https://arxiv.org/abs/2512.17102
- Peng Xia et al., “SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning”, arXiv:2602.08234. https://arxiv.org/abs/2602.08234
- Siru Ouyang et al., “SkillOS: Learning Skill Curation for Self-Evolving Agents”, arXiv:2605.06614. https://arxiv.org/abs/2605.06614
- Anthropic, “Extend Claude with skills”, Claude Code Docs. https://code.claude.com/docs/en/skills
- OpenAI, “Custom instructions with AGENTS.md”, Codex Docs. https://developers.openai.com/codex/guides/agents-md
- Google, “Provide Context with GEMINI.md Files”, Gemini CLI Docs. https://google-gemini.github.io/gemini-cli/docs/cli/gemini-md.html
- Google, “Gemini CLI Extensions”, Gemini CLI Docs. https://google-gemini.github.io/gemini-cli/docs/extensions/
- Nous Research, “Persistent Memory”, Hermes Agent Docs. https://hermes-agent.nousresearch.com/docs/user-guide/features/memory/
- Nous Research, “Skills System”, Hermes Agent Docs. https://hermes-agent.nousresearch.com/docs/user-guide/features/skills/
- pi.dev, “Package Catalog”. https://pi.dev/packages
- pi, “Skills”. https://hochej.github.io/pi-mono/coding-agent/skills/
- Agent Skills, “Agent Skills Overview”. https://agentskills.io/home
- Agent Skills, “Specification”. https://agentskills.io/specification
- badlogic, “pi-skills: Skills for pi coding agent”. https://github.com/badlogic/pi-skills
- Microsoft, “APM — Agent Package Manager”. https://github.com/microsoft/apm, https://microsoft.github.io/apm/
- haddock-development, “claude-reflect-system: Continual Learning & Self-improving skills system for Claude Code”. https://github.com/haddock-development/claude-reflect-system
- reshadat, “self-learning-claude: A framework for self-improving LLM systems through evolving context playbooks”. https://github.com/reshadat/self-learning-claude
- affaan-m, “everything-claude-code — continuous-learning skill”. https://github.com/affaan-m/everything-claude-code
- Yeachan-Heo, “oh-my-claudecode / oh-my-opencode”. https://github.com/yeachan-heo/oh-my-claudecode